Articles
- Page Path
- HOME > Restor Dent Endod > Volume 41(1); 2016 > Article
- Open Lecture on Statistics Statistical notes for clinical researchers: Sample size calculation 1. comparison of two independent sample means
- Hae-Young Kim
-
2015;41(1):-78.
DOI: https://doi.org/10.5395/rde.2016.41.1.74
Published online: December 30, 2015
Department of Health Policy and Management, College of Health Science, and Department of Public Health Sciences, Graduate School, Korea University, Seoul, Korea.
- Correspondence to Hae-Young Kim, DDS, PhD. Associate Professor, Department of Health Policy and Management, College of Health Science, and Department of Public Health Sciences, Graduate School, Korea University, 145 Anam-ro, Seongbuk-gu, Seoul, Korea 02841. TEL, +82-2-3290-5667; FAX, +82-2-940-2879; kimhaey@korea.ac.kr
©Copyrights 2016. The Korean Academy of Conservative Dentistry.
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/3.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
- 7,479 Views
- 113 Download
- 43 Crossref
Asking advice about sample size calculation is one of frequent requests from clinical researchers to statisticians. Sample size calculation is essential to obtain the results as the researcher expects as well as to interpret the statistical results as reasonable one. Usually insignificant results from studies with too small sample size may be subjects to suspicion about false negative, and also significant ones from those with too large sample size may be subjects to suspicion about false positive. In this article, the principles in sample size calculation will be introduced and practically some examples will be displayed using a free software, G*Power.1
Why sample size determination is important?
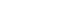
Sample size determination procedure should be performed prior to an experiment in most clinical studies. To draw the conclusion of an experiment, we usually interpret the p values of significance tests. A p value is directly linked to the related test statistic calculated by using standard errors, which is a function of sample size and standard deviation (SD). Therefore, the results of significance test differ depending on the sample size. For example, in comparison of two sample means, the standard error can be expressed as the standard deviation multipled by root-squared 2/sample sizes (SD / 2 n 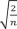 ), if equal sample size and equal variance between two groups are assumed. When the sample size is inappropriate, our interpretations based on p values could not be reliable. If we have too small sample size, we are apt to find a small test statistic, a large p value, and statistical insignificance even when the mean difference is substantial. In contrast, larger sample size may lead into a larger test statistic, a smaller p value, and statistical significance even when the mean difference is just trivial. A statistical significance test result may be unreliable when a sample size is too small, and it may be clinically meaningless when too large. Therefore, to make the significance test reliable and clinically meaningful, we need to plan a study with an appropriate sample size. The previous article about effect size in Statistical Notes for Clinical Researchers series provided a more detailed explanation about this issue.2
), if equal sample size and equal variance between two groups are assumed. When the sample size is inappropriate, our interpretations based on p values could not be reliable. If we have too small sample size, we are apt to find a small test statistic, a large p value, and statistical insignificance even when the mean difference is substantial. In contrast, larger sample size may lead into a larger test statistic, a smaller p value, and statistical significance even when the mean difference is just trivial. A statistical significance test result may be unreliable when a sample size is too small, and it may be clinically meaningless when too large. Therefore, to make the significance test reliable and clinically meaningful, we need to plan a study with an appropriate sample size. The previous article about effect size in Statistical Notes for Clinical Researchers series provided a more detailed explanation about this issue.2
), if equal sample size and equal variance between two groups are assumed. When the sample size is inappropriate, our interpretations based on p values could not be reliable. If we have too small sample size, we are apt to find a small test statistic, a large p value, and statistical insignificance even when the mean difference is substantial. In contrast, larger sample size may lead into a larger test statistic, a smaller p value, and statistical significance even when the mean difference is just trivial. A statistical significance test result may be unreliable when a sample size is too small, and it may be clinically meaningless when too large. Therefore, to make the significance test reliable and clinically meaningful, we need to plan a study with an appropriate sample size. The previous article about effect size in Statistical Notes for Clinical Researchers series provided a more detailed explanation about this issue.2
Information needed for sample size determination
When we compare two independent group means, we need following information for sample size determination.
Basically we need to suggest expected group means and standard deviations. Those information can be obtained from similar previous studies or pilot studies. If there is no previous study, we have to guess the values reasonably according to our knowledge. Also we can calculate the effect size, Cohen's d, as mean difference divided by SD.
If variances of two groups are different, SD is given as S D 1 2 + S D 2 2 2  under assumption of equal sample size. To 2 detect smaller effect size as statistically significant, a larger sample size is needed as shown in Table 1.
under assumption of equal sample size. To 2 detect smaller effect size as statistically significant, a larger sample size is needed as shown in Table 1.
under assumption of equal sample size. To 2 detect smaller effect size as statistically significant, a larger sample size is needed as shown in Table 1.Type one error level (α - error level) or level of significance needs to be decided. The significance test may be one-sided or two-sided. For one-sided test we apply Zα for one-sided test, and Zα/2 for two-sided test. Usually for α - error level of 0.05, Zα=0.05 = 1.645 for one sided test and Zα/2=0.025 = 1.96 for two-sided test (Table 2).
Power is probability of rejecting null hypothesis when the alternative hypothesis is true. Power is obtained as one minus type two error (1 - β error), which means probability of accepting null hypothesis when the alternative hypothesis is true. The most frequently used power levels are 0.8 or 0.9, corresponding to Z1-β=0.80 = 0.84 and Zβ=0.90 = 1.28 (Table 2).
Allocation ratio of two groups needs to be determined.
During the experiment period, some subjects may drop out due to various reasons. We need to increase the initial sample size to get adequate sample size at final observation of the study. If 10% of drop-outs are expected, we need to increase initial sample size by 10%.
Calculation of sample size
When we compare two independent group means, we can use the following simple formula to determine an adequate sample size. Let's assume following conditions: mean difference (mean 1 - mean 2) = 10, SD (σ) = 10, α - error level (two-sided) = 0.05 (corresponding Zα/2 = 1.96), power level = 0.8 (corresponding Zβ = 0.84), and allocation ratio N2 / N1 = 1. The sample size was calculated as 16 subjects per group.
The sample size calculation can be accomplished using various statistical softwares. Table 1 shows determined sample sizes for one-sided tests according to various mean difference, size of standard deviation, level of significance, and power level, using a free software G*Power. The determined sample size of '17' in Table 1 is found on the exactly same condition above. Larger sample size is needed as effect size decreases, level of significance decreases, and power increases.
Sample size determination procedure using G*Power
G*Power is a free software. You can download it at http://www.gpower.hhu.de/. You can determine an appropriate sample size in comparison of two independent sample means by performing the following steps.
Step 1: Selection of statistical test types:
Menu: Tests-Means-Two independent groups
Step 2: Calculation of effect size:
Menu: Determine - mean & SD for 2 groups - calculate and transfer to main window
Step 3: Select one-sided (tails) or two-sided (tails) test
Step 4: Select α - error level : one-sided α/2 = two-sided α
Step 5: Select power level
Step 6: Select allocation ratio
Step 7: Calculation of sample size
Menu: Calculate
Example 1) Effect size = 2
Two sided (tails) test
Two-sided α - error level=0.05 (one-sided α=0.025)
Power = 0.8
Allocation ratio N2 / N1 = 1.
Appropriate sample size calculated: N1 = 8, N2 = 8.Example 2) Effect size = 1
One sided (tails) test
α - error level = 0.025
Power = 0.8
Allocation ratio N2 / N1 = 2.
Appropriate sample size calculated: N1 = 13, N2 = 25.- 1. Faul F, Erdfelder E, Lang AG, Buchner A. G*Power 3: a flexible statistical power analysis program for the social, behavioral, and biomedical sciences. Behav Res Methods 2007;39:175-191.ArticlePubMedPDF
- 2. Kim HY. Statistical notes for clinical researchers: effect size. Restor Dent Endod 2015;40:328-331.ArticlePubMedPMC
REFERENCES
Table 1
Examples of determined adequate sample size for one-sided tests according to various mean difference, size of standard deviation, level of significance, and power level (allocation ratio N2 / N1 = 1)
Table 2
Significance level for one-sided test, power and corresponding Z values
Tables & Figures
REFERENCES
Citations
Citations to this article as recorded by 
- The Levels and Significance of Serum Sex Hormones, BMP-7, and RBP in Adult Male Patients With Primary Nephrotic Syndrome
Ying Zhou, Lai Zhang
British Journal of Hospital Medicine.2026;[Epub] CrossRef - Using Smartphone-Based Digital Phenotyping to Predict Relapse in Serious Mental Disorders Among Slum Residents in Dhaka, Bangladesh: Protocol for a Machine Learning Study
Nadia Alam, Chayon Kumar Das, Neelabja Roy, Domenico Giacco, Swaran P Singh, Sagar Jilka
JMIR Research Protocols.2026; 15: e79826. CrossRef - Relation between Hypertension and Hearing Loss: A Study of Hypertensive Patients in a Tertiary Hospital in Lagos, Nigeria
Chinyere Nkiruka Asoegwu, Nkiruka Augusta Wakwe, Janet Ngozi Ajuluchukwu, Clement Chukwuemeka Nwawolo
Nigerian Postgraduate Medical Journal.2026; 33(1): 134. CrossRef - Auditory Working Memory in Children Using Cochlear Implants
Deepika Jayachandran, Sarah Zahir
Indian Journal of Otolaryngology and Head & Neck Surgery.2026; 78(3): 1625. CrossRef - Effect of probiotic lozenges on improvement in tympanometric classification within 12 weeks in children aged 3–6 years with adenoid hypertrophy and otitis media with effusion undergoing non-surgical management: a randomized controlled trial
Jun Shi, Yu Liu, Xiaoning Chen, Xiaofei Hou, He Chen, Luomeng Chen, Le Li
Frontiers in Cellular and Infection Microbiology.2026;[Epub] CrossRef - MAAIA: A Multidimensional Anomaly Attribution Method for Accurate Evaluation of A/B Testing Effects
梓豪 先
Advances in Applied Mathematics.2026; 15(03): 602. CrossRef - Comparison of Platelet-Rich Plasma Therapy Versus Intralesional Triamcinolone Acetonide in the Treatment of Alopecia Areata: A Single-Blinded, Randomised Controlled Trial
Yashika Sethi, Garima Dabas, Pravesh Yadav, Vivek Sagar, Geetika Chhabra
Indian Journal of Dermatology.2026;[Epub] CrossRef - Human whole-blood NAD+ levels do not vary with age or lifestyle interventions
Maria M. Trętowicz, Angelique M. L. Scantlebery, Bauke V. Schomakers, Kaan D. Eroğlu, Michel van Weeghel, Vera Spek, Kasper T. Vinten, Luc Legon, Evrim Coskun, Fernando Millan-Domingo, Gloria Olaso-Gonzalez, Maria Carmen Gomez-Cabrera, Silvia Montoro-Garc
Nature Metabolism.2026; 8(6): 1282. CrossRef - Denoising Improves Cross‐Scanner and Cross‐Protocol Test–Retest Reproducibility of Diffusion Tensor and Kurtosis Imaging
Benjamin Ades‐Aron, Santiago Coelho, Gregory Lemberskiy, Jelle Veraart, Steven H. Baete, Timothy M. Shepherd, Dmitry S. Novikov, Els Fieremans
Human Brain Mapping.2025;[Epub] CrossRef - Disinfection of Human and Porcine Corneal Endothelial Cells by Far-UVC Irradiation
Ben Sicks, Martin Hessling, Kathrin Stucke-Straub, Sebastian Kupferschmid, Ramin Lotfi
Medicina.2025; 61(3): 416. CrossRef - Implementation and Practice of the Antimicrobial Stewardship Program (ASP) in Various Healthcare Settings in Al Ahsa
Lorina Ineta Badger-Eme, Promise Madu Emeka, Sayed Abdul Qadar Quadri, Hussein Yousef AlHelal, Abdulrahim Alabdulsal, Mohammed Abdulwahab Buhalim, Omer Abdullah Alrasheed, Muktar Ali AlHelal
International Journal of Pharmacology.2025; 21(2): 270. CrossRef - Prevalence and determinants of insulin resistance in recovered COVID-19 and uninfected residents of two regional capitals in Ghana: An observational study
Ansumana Sandy Bockarie, Leonard Derkyi-Kwarteng, Jeffrey Amankona Obeng, Richard Kujo Adatsi, Ebenezer Aniakwaa-Bonsu, Charles Apprey, Jerry Ampofo-Asiama, Samuel Acquah, Giridhara Rathnaiah Babu
PLOS Global Public Health.2025; 5(4): e0004506. CrossRef - Effects of a multi-level intervention on pedestrians’ behavior among Iranian health worker supervisors: a randomized controlled trial
Sepideh Harzand-Jadidi, Maryam Vatandoost, David C. Schwebel, Homayoun Sadeghi-bazargani, Fatemeh Bakhtari Aghdam, Hamid Allahverdipour
Frontiers in Public Health.2025;[Epub] CrossRef - Effectiveness of tele-counseling for patients with alcohol dependence syndrome – A randomized control trial
Pranesh Ram Ranganathan, Raghuthaman Gopal, Sureshkumar Ramasamy
Industrial Psychiatry Journal.2025; 34(2): 264. CrossRef - Hydration and Fluid Intake in Basketball Players During Training: Comparison of Different Age Categories
Abdurrahim Kaplan, Bayram Ceylan, Bilgehan Baydil, Jožef Šimenko
Applied Sciences.2025; 15(19): 10304. CrossRef - Peritraumatic distress and its relationship to appliance-related orthodontic emergencies in orthodontic patients during the COVID-19 lockdown in Shanghai, China: a cross-sectional study
Li’an Yang, Jie Zhang, Yuhsin Choi, Shuting Zhang, Wa Li, Kai Liu, Pei Tang, Jianyong Wu, Xin Yang
BMJ Open.2025; 15(8): e095959. CrossRef - Role of biomarkers in predicting disease severity in acute dengue and SARs-CoV-2-Infected patients
Eakkawit Yamasmith, Jennifer D. Kinslow, Michael G. Berg, Gavin A. Cloherty, James N. Moy, Alan L. Landay, Yupin Suputtamongkol, Wiwit Tantibhedhyangkul
BMC Infectious Diseases.2025;[Epub] CrossRef - Application of sugar-free cola solution based on the ICOCFAS score in oral care of non-artificial airway patients with severe neurological conditions
Qingmei Wang, Yuanyuan Fan, Mei Chen, Ping Chen
Frontiers in Medicine.2025;[Epub] CrossRef - Estimation of urea and creatinine in vaginal fluid in preterm prelabour rupture of membranes
Heena Ladher, Sunil Kumar Juneja, Shweta Gupta, Navjot Bajwa, Amandeep Kaur, Prannav Jain
The Journal of Obstetrics and Gynecology of India.2025;[Epub] CrossRef - Analysis of the Use of Sample Size and Effect Size Calculations in a Temporomandibular Disorders Randomised Controlled Trial—Short Narrative Review
Grzegorz Zieliński, Piotr Gawda
Journal of Personalized Medicine.2024; 14(6): 655. CrossRef - Asymptomatic bacteriuria and its associated fetomaternal outcomes among pregnant women delivering at Bugando Medical Centre in Mwanza, Tanzania
Colman Mayomba, Dismas Matovelo, Richard Kiritta, Zengo Kashinje, Jeremiah Seni, Seth Agyei Domfeh
PLOS ONE.2024; 19(10): e0303772. CrossRef - Obesity Influences T CD4 Lymphocytes Subsets Profiles in Children and Adolescent's Immune Response
Rafael Silva Lima, Mayara Belchior-Bezerra, Daniela Silva de Oliveira, Roberta dos Santos Rocha, Nayara I Medeiros, Rafael T Mattos, Isabelle Camile dos Reis, Aiessa Santos Marques, Pedro WS Rosário, Maria Regina Calsolari, Rodrigo Correa-Oliveira, Walder
The Journal of Nutrition.2024; 154(10): 3133. CrossRef - Clinical and psychological impact of lip repositioning surgery in the management of excessive gingival display
Asmita Dawadi, Manoj Humagain, Simant Lamichhane, Birat Sapkota
The Saudi Dental Journal.2024; 36(1): 84. CrossRef - Fifteen-year recall period on zirconia-based single crowns and fixed dental prostheses. A prospective observational study
Shahnawaz Khijmatgar, Margherita Tumedei, Guilia Tartaglia, Michele Crescentini, Gaetano Isola, Ernesto Sidoti, Chiarella Sforza, Massimo Del Fabbro, Gianluca Martino Tartaglia
BDJ Open.2024;[Epub] CrossRef - A Serious Game for Enhancing Rescue Reasoning Skills in Tactical Combat Casualty Care: Development and Deployment Study
Siyue Zhu, Zenan Li, Ying Sun, Linghui Kong, Ming Yin, Qinge Yong, Yuan Gao
JMIR Formative Research.2024; 8: e50817. CrossRef - Shifts in Narrative Perspectives Consume Attentional Resources and Facilitate Reading Engagement
Jian Jin, Siyun Liu
Scientific Studies of Reading.2023; 27(5): 393. CrossRef - Effectiveness of Malaria Free Zone Program on the Knowledge, Attitude and Practice of Malaria Prevention among university students in Conakry, Guinea: Protocol of a Randomized Controlled Trial
Aicha Sano, Dhashani A/P Sivaratnam, Norliza Ahmad, Alioune Camara, Poh Ying Lim
Malaysian Journal of Medicine and Health Sciences.2023; 19(2): 321. CrossRef - Evaluation of carotid artery Doppler measurements in late-onset fetal growth restriction: a cross-sectional study
Gokce Naz Kucukbas, Yasemin Doğan
Journal of Surgery and Medicine.2023; 7(10): 673. CrossRef - Assessment of changes in Streptococcus pyogenes levels using N-acetylgalactosamine-6-sulfatase marker and pharyngeal airway space with appliance therapy in mouth breathers – An ELISA-based study
Meha Singh, Shivani Mathur, Pulkit Jhingan, Anshi Jain
Journal of Indian Society of Pedodontics and Preventive Dentistry.2023; 41(2): 111. CrossRef - Reaffirming Adverse Events Related to Lung Cancer Survivors’ Target Therapies and Their Apparent Effects on Fear of Cancer Progression, Anxiety, and Depression
Chu-Chun Yu, Chia-Yu Chu, Yeur-Hur Lai, Chia-Tai Hung, Jui-Chun Chan, Yen-Ju Chen, Hui-Te Hsu, Yun-Hsiang Lee
Cancer Nursing.2023; 46(6): 488. CrossRef - Effect of depot medroxyprogesterone acetate on cardiometabolic risk factors among women of reproductive age in Rwanda: A prospective cohort study
Evelyne Kantarama, Dieudonne Uwizeye, Annette Uwineza, Claude Mambo Muvunnyi
Indian Journal of Medical Sciences.2023; 76: 28. CrossRef - Designing prototype rapid test device at qualitative performance to detect residue of tetracycline in chicken carcass
Mochamad Lazuardi, Eka Pramyrtha Hestianah, Tjuk Imam Restiadi
Veterinary World.2022; : 1058. CrossRef - To Calibrate or not to Calibrate? A Methodological Dilemma in Experimental Pain Research
Waclaw M. Adamczyk, Tibor M. Szikszay, Hadas Nahman-Averbuch, Jacek Skalski, Jakub Nastaj, Philip Gouverneur, Kerstin Luedtke
The Journal of Pain.2022; 23(11): 1823. CrossRef - Intravenous Methylprednisolone Pulse Therapy Versus Intravenous Immunoglobulin in the Prevention of Coronary Artery Disease in Children with Kawasaki Disease: A Randomized Controlled Trial
Nahid Aslani, Seyed-Reza Raeeskarami, Ehsan Aghaei-Moghadam, Fatemeh Tahghighi, Raheleh Assari, Payman Sadeghi, Vahid Ziaee
Cureus.2022;[Epub] CrossRef - Bioactivity effects of extracellular matrix proteins on apical papilla cells
Maria Luísa LEITE, Diana Gabriela SOARES, Giovana ANOVAZZI, MON Filipe Koon Wu, Ester Alves Ferreira BORDINI, Josimeri HEBLING, Carlos Alberto DE SOUZA COSTA
Journal of Applied Oral Science.2021;[Epub] CrossRef - Mapping QTL associated with partial resistance to Aphanomyces root rot in pea (Pisum sativum L.) using a 13.2 K SNP array and SSR markers
Longfei Wu, Rudolph Fredua-Agyeman, Sheau-Fang Hwang, Kan-Fa Chang, Robert L. Conner, Debra L. McLaren, Stephen E. Strelkov
Theoretical and Applied Genetics.2021; 134(9): 2965. CrossRef - Oxidized Low-Density Lipoprotein Drives Dysfunction of the Liver Lymphatic System
Matthew A. Burchill, Jeffrey M. Finlon, Alyssa R. Goldberg, Austin E. Gillen, Petra A. Dahms, Rachel H. McMahan, Anne Tye, Andrew B. Winter, Julie A. Reisz, Eric Bohrnsen, Johnathon B. Schafer, Angelo D’Alessandro, David J. Orlicky, Michael S. Kriss, Hugo
Cellular and Molecular Gastroenterology and Hepatology.2021; 11(2): 573. CrossRef - Comparing 24-hour symptom triggered therapy and fixed schedule treatment for alcohol withdrawal symptoms – A randomized control study
Raghuthaman Gopal, Sushith Sugathan Chennatte, Shilpa S.
Asian Journal of Psychiatry.2020; 48: 101888. CrossRef - Rejuvenation of three germ layers tissues by exchanging old blood plasma with saline-albumin
Melod Mehdipour, Colin Skinner, Nathan Wong, Michael Lieb, Chao Liu, Jessy Etienne, Cameron Kato, Dobri Kiprov, Michael J. Conboy, Irina M. Conboy
Aging.2020; 12(10): 8790. CrossRef - Management of haemorrhoids: protocol of an umbrella review of systematic reviews and meta-analyses
Min Chen, Tai-Chun Tang, Tao-Hong He, Yong-Jun Du, Di Qin, Hui Zheng
BMJ Open.2020; 10(3): e035287. CrossRef - mTOR/HDAC1 Crosstalk Mediated Suppression of ADH1A and ALDH2 Links Alcohol Metabolism to Hepatocellular Carcinoma Onset and Progression in silico
Kashif Rafiq Zahid, Shun Yao, Abdur Rehman Raza Khan, Umar Raza, Deming Gou
Frontiers in Oncology.2019;[Epub] CrossRef - Enhancing Effect of Elastinlike Polypeptide-based Matrix on the Physical Properties of Mineral Trioxide Aggregate
Ji-Hyun Jang, Chung-Ok Lee, Hyun-Jung Kim, Sahng G. Kim, Seung-Wuk Lee, Sun-Young Kim
Journal of Endodontics.2018; 44(11): 1702. CrossRef - Statistical notes for clinical researchers: Sample size calculation 2. Comparison of two independent proportions
Hae-Young Kim
Restorative Dentistry & Endodontics.2016; 41(2): 154. CrossRef
 ePub Link
ePub Link Cite
CiteStatistical notes for clinical researchers: Sample size calculation 1. comparison of two independent sample means
Statistical notes for clinical researchers: Sample size calculation 1. comparison of two independent sample means
Examples of determined adequate sample size for one-sided tests according to various mean difference, size of standard deviation, level of significance, and power level (allocation ratio N2 / N1 = 1)
| Variation | Group 1 Mean ± SD | Group 2 Mean ± SD | Mean difference | SD | Effect size | Level of significance (one-sided) | Power | Sample size per group |
|---|---|---|---|---|---|---|---|---|
| Effect size | 40 ± 10 | 20 ± 10 | 20 | 10 | 2 | 0.025 | 0.8 | 6 |
| 40 ± 10 | 30 ± 10 | 10 | 10 | 1 | 0.025 | 0.8 | 17 | |
| 40 ± 10 | 35 ± 10 | 5 | 10 | 0.5 | 0.025 | 0.8 | 64 | |
| 40 ± 10 | 39 ± 10 | 1 | 10 | 0.1 | 0.025 | 0.8 | 1571 | |
| Standard deviation | 40 ± 20 | 20 ± 20 | 20 | 20 | 1 | 0.025 | 0.8 | 17 |
| 40 ± 13.3 | 40 ± 13.3 | 20 | 13.3 | 1.5 | 0.025 | 0.8 | 9 | |
| 40 ± 6.7 | 40 ± 6.7 | 20 | 6.7 | 3 | 0.025 | 0.8 | 4 | |
| Level of significance | 40 ± 10 | 30 ± 10 | 10 | 10 | 1 | 0.05 | 0.8 | 14 |
| 40 ± 10 | 30 ± 10 | 10 | 10 | 1 | 0.01 | 0.8 | 22 | |
| 40 ± 10 | 30 ± 10 | 10 | 10 | 1 | 0.001 | 0.8 | 34 | |
| Power | 40 ± 10 | 30 ± 10 | 10 | 10 | 1 | 0.025 | 0.7 | 14 |
| 40 ± 10 | 30 ± 10 | 10 | 10 | 1 | 0.025 | 0.9 | 23 | |
| 40 ± 10 | 30 ± 10 | 10 | 10 | 1 | 0.025 | 0.95 | 27 |
SD, standard deviation.
Significance level for one-sided test, power and corresponding Z values
| Alpha or Beta | Zα or Zβ | |
|---|---|---|
| 0.005 | 2.58 | Significance level = 0.01 for 2 sided test |
| 0.025 | 1.96 | Significance level = 0.05 for 2 sided test |
| 0.05 | 1.645 | Significance level = 0.1 for 2 sided test |
| 0.1 | 1.28 | Power (1 - β) = 0.9 |
| 0.2 | 0.84 | Power (1 - β) = 0.8 |
Table 1 Examples of determined adequate sample size for one-sided tests according to various mean difference, size of standard deviation, level of significance, and power level (allocation ratio N2 / N1 = 1)
SD, standard deviation.
Table 2 Significance level for one-sided test, power and corresponding Z values