Articles
- Page Path
- HOME > Restor Dent Endod > Volume 40(4); 2015 > Article
- Open Lecture on Statistics Statistical notes for clinical researchers: effect size
- Hae-Young Kim
-
2015;40(4):-331.
DOI: https://doi.org/10.5395/rde.2015.40.4.328
Published online: October 2, 2015
Department of Health Policy and Management, College of Health Science, and Department of Public Health Sciences, Graduate School, Korea University, Seoul, Korea.
- Correspondence to Hae-Young Kim, DDS, PhD. Associate Professor, Department of Health Policy and Management, College of Health Science, and Department of Public Health Sciences, Graduate School, Korea University, 145 Anam-ro, Seongbuk-gu, Seoul, Korea 02841. TEL, +82-2-3290-5667; FAX, +82-2-940-2879; kimhaey@korea.ac.kr
©Copyrights 2015. The Korean Academy of Conservative Dentistry.
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/3.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
- 14,018 Views
- 130 Download
- 89 Crossref
In most clinical studies, p value is the final result of data analysis. A small p value is interpreted as a significant difference between the experimental group and the control group. However, reporting p value is not enough to know the actual difference. Problem of p value is that it depends on the sample size, n. Even a trivial meaningless difference can result in an extremely small p value when sample size is large. To make up this weak point, we need to report the 'effect size' as well as the p value. Effect size is a simple way to show the actual difference, which is independent of the sample size.
1. Reporting p value is not enough
In statistical testing we set a null hypothesis first and calculate the test statistic such as t values under an assumption of the null hypothesis. Finally, a p value is obtained which represents the probability of observing the current data due to chance when the null hypothesis is true. In most scientific articles, we usually make conclusion based on p values compared to the alpha error level chosen, e.g., 0.05. A smaller p value than alpha level is interpreted as a statistical significance. However, there are serious problems in relying on the p value only.
First, depending on the sample size, a wide range of p values can be obtained with the same size of difference, which can lead to contradictory results: either statistically significant or insignificant conclusions. Examples 1 and 2 in Table 1 have the same trivial difference of 3 between before and after treatments, assuming a clinically meaningful difference as 10. Two results were contradictory: statistically significant (p = 0.001, Example 2) and insignificant (p = 0.382, Example 1) depending on whether the sample size is large (n =10,000) or small (n =100). Moreover, as appeared in Example 2, it is a serious problem that clinically meaningless condition is concluded as statistically significant. The treatment in example 2 is clinically insignificant but statistically significant! What would you reasonably conclude on this case? This is a problem caused by using inappropriately large sample sizes.
Second, the information provided by the size of p value is confusing, because it is confounded by the sample size. We may expect that a small p value can tell us some information on how much difference exists between the observed data and the assumption of null hypothesis. However, the same size of p values can be obtained from quite different situations. Example 2 with a trivial effect and larger sample size and Example 3 with a substantial effect and smaller sample size both show the same p value 0.001 in Table 1. The result shows that p values are confounded with the sample size.
Two problems above can be overcome by controlling the sample size. To avoid this discordant situation, sample size determination procedure must be performed in the design stage in an experimental study. We generally need to calculate appropriate sample size in consideration with difference, SD, alpha error and power in the study design stage. The conclusion of significance testing is reliable only when an appropriate sample size was applied in a study. When we analyze a survey data with a large sample size, we need to consider the effect of large sample size in the interpretation of the test results.
Also the weakness of p value can be compensated by considering the effect size coincidently. As shown in Table 1, effect sizes exactly reflect the magnitude of actual effect, as displayed by 0.03 for a trivial difference and 0.3 for a substantial one.
2. What is effect size?
'Effect size' is simply a way of quantifying difference between compared groups, in other words, the actual effect.1 While a p value has an important meaning in statistical inference, an effect size is expressing a descriptive importance. In Table 1, the effect sizes were expressed as the difference between two group means divided by the standard deviation of the group. When we compared Example 2 and Example 3, their effect sizes are a quite different as 0.03 and 0.3, while their p values are the same. Let's suppose clinicians generally think a change of at least '10' is clinically meaningful while a change of 3 after treatment is negligible. Therefore, they would not apply the treatment for the small change 3, even though the statistical significance test concluded the treatment is effective based on highly significant p value. Contrarily, they would apply the treatment in Example 3 because they can expect a substantial change of '30', and the statistical test concluded its significance. The results show that effect size exactly reflects the actual difference or effect. Therefore, reporting both the p value and the effect size is necessary in order to consider both statistical significance and actual clinical significance.
3. Types of effect size
Generally, there are two types of common effect size indices: standardized difference between groups and measures of association between groups. Table 2 shows the types of effect size indices and general standards of small, medium, and large effect for each type of effect size.
-
Between groups
1) Cohen's d or Glass's Δ: Defined by difference between two group means divided by standard deviation for continuous outcomes. Cohen's d is calculated by dividing pooled standard deviation under assumption of the equal variances while Glass's Δ is obtained by dividing the standard deviation of control group.
2) Odds ratio: Defined by ratio of odds of two compared groups for binary outcomes.
3) Relative ratio: Defined by ratio of proportions of two compared groups for binary outcomes.
-
Measures of association
4. Interpretation of effect size
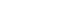
Then, how would we interpret the degree of effect size? An effect size is exactly equivalent to a Z score of a standard normal distribution. Assume that all data are normally distributed. If Cohen's d is calculated to be zero, it means that there is no mean difference between two comparative groups and the position of the mean of experimental group is exactly the same with the mean of control group. Therefore, 50% of observations in control group locate below the mean of experimental group (Table 3). The relative 'small' effect size '0.2' means the mean of experimental group is located at 0.2 standard deviation above the mean of control group. The Z score of 0.2 is at 58th percentile which have 58% of observations below in control group (Figure 1). Similarly, the Cohen's d values 0.5 and 0.8 locate at 69th and 79th percentile of the distribution of the control group, respectively.
5. Conversion of effect sizes to Pearson r correlation coefficient
Pearson r correlation coefficient is an effect size which is widely understood and frequently used. Converting various statistic values including t or F into Pearson r correlation coefficient may be advantageous because it facilitates interpretation. Also Cohen's d can be converted into r. Table 4 provides the conversion formula and a brief explanation.
6. Summary
Though p values give information on statistical significance, they are confounded with the sample size. Effect size can make up the weak point, by providing information on the actual effect which is independent of the sample size. Therefore, reporting the effect size as well as the p value is recommended.
- 1. Coe R. It's the effect size, stupid: what effect size is and why it is important. Paper presented at the 2002 Annual Conference of British Education Research Association, University of Exeter, Exeter, Devon, England, September 12-14, 2002. updated 2015 Sep 6]. Available from: http://www.leeds.ac.uk/educol/documents/00002182.htm.
- 2. Sullivan GM, Feinn R. Using effect size - or why p value is not enough. J Grad Med Educ 2012;4:279-282.PubMedPMC
- 3. Becker LA. Effect size (ES). updated 2015 Sep 6]. Available from: http://www2.jura.uni-hamburg.de/instkrim/kriminologie/Mitarbeiter/Enzmann/Lehre/StatIIKrim/EffectSizeBecker.pdf.
REFERENCES
Figure 1
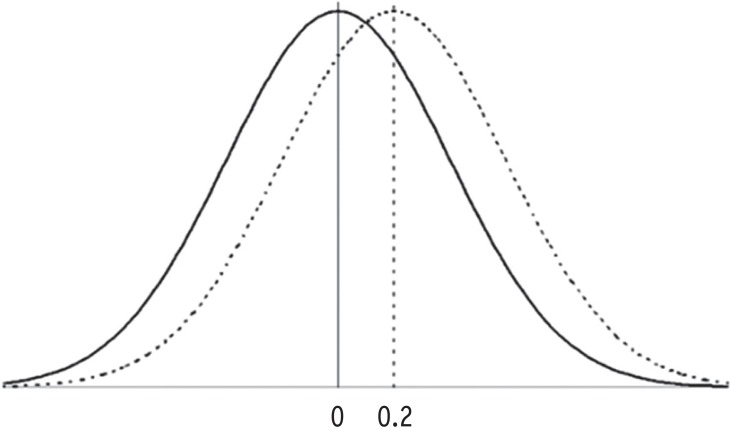
Distribution of control group (solid line) and experimental group (dotted line), and position of Cohen's d = 0.2.1
Table 1
Examples of results of significant testing using p value and comparative effect size
Table 2
Common effect size indices2
Table 3
| Relative size | Effect size | % of control group below the mean of experimental group |
|---|---|---|
| 0.0 | 50% | |
| Small | 0.2 | 58% |
| Medium | 0.5 | 69% |
| Large | 0.8 | 79% |
| 1.4 | 92% |
Table 4
Conversion from various statistics to Perason r correlation coefficient association measures3
Tables & Figures
REFERENCES
Citations
Citations to this article as recorded by 
- Perceived stress and death-related distress in older adults: Exploring the role of social support and emotional loneliness
Gökmen Arslan, Deniz Say Şahin
Death Studies.2026; 50(5): 806. CrossRef - Unraveling interoceptive processing and action dynamics: Exploring neural and psychological responses to food cues using fMRI
Nastaran Malmir, Hamed Ekhtiari, Ali Farhoudian, Somaye Robatmili, Michael Nitsche
Appetite.2026; 216: 108239. CrossRef - Citrate-capped AuNPs-induced redox reprogramming modulates the TP53–BAX/BCL2–CASP3 Axis, reinforcing antioxidant defense and promoting apoptotic signaling in liver Cancer
Alaa Elmetwalli, Sara Abdelsayed, Mervat G. Hassan, Ibtisam Aboud Almutairi, Deema Kamal Sabir, Hassnaa Elsherbiny, Ashraf Elsayed
Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy.2026; 344: 126630. CrossRef - Relationships between single-leg hop for distances of four types at 6 Months after anterior cruciate ligament reconstruction and knee joint function, disturbed body perception, and movement-specific fear
Shinya Fujita, So Tanaka, Yuta Tomooka, Hirofumi Yamashita, Akira Mibu, Masami Tokunaga, Takaaki Yoshimoto, Tomohiko Nishigami
Physical Therapy in Sport.2026; 77: 21. CrossRef - Phenotyping of Patients Seeking Third or Higher-Order Metabolic Bariatric Surgery
Michal Zaichyk-Segal, Orit Yogev, Chaya Chweiger, Galit Goldzak-Kunik, Roni Elran-Barak, Shiri Sherf-Dagan
Obesity Surgery.2026; 36(3): 988. CrossRef - Association Between Multidimensional Housing Precarity and Cognitive Function Among Older Adults: Findings from the National Survey of Older Koreans, 2023
Seong-Uk Baek, Jin-Ha Yoon
Journal of General Internal Medicine.2026;[Epub] CrossRef - Clinical Investigation and Statistical Analysis Improve the Metrological Reliability of Forehead Infrared Radiation Thermometers
Pedro Diniz, Rafael Farias, Klaus Quelhas, Rodrigo Costa-Felix
MAPAN.2026; 41(1): 211. CrossRef - Sober or Not, You Still Learn: Implicit and Explicit Motor Learning Unaffected by Moderate Alcohol
José Eduardo dos Martírios Luz, Flavio Henrique Bastos, Guilherme Menezes Lage, Marina Gonçalves Leal, José Roberto de Maio Godoi Filho, Giordano Marcio Gatinho Bonuzzi
Journal of Motor Behavior.2026; 58(3): 300. CrossRef - Interpreting Research Findings in Endodontics: A Biostatistical Primer
Mehran Farajollahi, Amir Azarpazhooh, Ali Nosrat, Shima Saber Tahan, Ove A. Peters
Journal of Endodontics.2026;[Epub] CrossRef - Feasibility study examining the short-term effects of Sonic Augmentation Technology™
Lourdes P. Dale, Audrey N. Dana, Carrie E. Lee, Hannah Lamont, Donnalea Van Vleet Goelz, Caitlin V. Dale, Parmida Nazarloo, Mark McIntosh, Steven P. Cuffe
Frontiers in Psychiatry.2026;[Epub] CrossRef - circRET-mediated regulation of RET influences enteric neural crest cell development in Hirschsprung disease
Yingnan Yan, Juping Wang, Fangzheng Zhao, Yang Wang
American Journal of Physiology-Gastrointestinal and Liver Physiology.2026; 331(1): G73. CrossRef - Comparative Effects of Therapeutic Exercise and Manual Therapy Techniques on Self-Reported Disability in Chronic Non-Specific Low Back Pain: A Network Meta-Analysis
Miguel Robles-García, Juan Luis Sánchez González, José Luis Sánchez-Sánchez, Laura Calderón-Díez, Miguel Santos Del Rey, Javier Martín-Vallejo
Journal of Clinical Medicine.2026; 15(12): 4809. CrossRef - The Association Between Urinary Incontinence With Pelvic Pain and Sensory‐Motor Function in Older Women With Stroke
Fatih Özden, Yalcin Golcuk, Özgür Nadiye Karaman, Mehmet Özkeskin
Neurourology and Urodynamics.2025; 44(1): 165. CrossRef - Metabolic Profiles of Offspring Born From Biopsied Embryos from Toddlerhood to Preschool Age
Jialin Zhao, Shuo Li, Miaomiao Ban, Shuzhe Gao, Linlin Cui, Junhao Yan, Xiaohe Yang, Jincheng Li, Yiyuan Zhang, Shengnan Guan, Wei Zhou, Xuan Gao, Zi-Jiang Chen
The Journal of Clinical Endocrinology & Metabolism.2025; 110(4): e980. CrossRef - The neural activity of auditory conscious perception
Kate L. Christison-Lagay, Aya Khalaf, Noah C. Freedman, Christopher Micek, Sharif I. Kronemer, Mariana M. Gusso, Lauren Kim, Sarit Forman, Julia Ding, Mark Aksen, Ahmad Abdel-Aty, Hunki Kwon, Noah Markowitz, Erin Yeagle, Elizabeth Espinal, Jose Herrero, S
NeuroImage.2025; 308: 121041. CrossRef - Weight-adjusted-waist index is associated with increased risk of sleep disturbances in the U.S. adult population: an analysis of NHANES 2007–2012
Haiping Xie, Chuhui Chen, Ting Li, Lizhen Xu, Jixing Liang, Junping Wen, Gang Chen, Liangchun Cai
Eating and Weight Disorders - Studies on Anorexia, Bulimia and Obesity.2025;[Epub] CrossRef - Long-Term Changes in Parameters of Bone Quality in Kidney Transplant Recipients Treated with Denosumab
Francesco Pollastri, Angelo Fassio, Pietro Manuel Ferraro, Stefano Andreola, Giovanni Gambaro, Andrea Spasiano, Chiara Caletti, Lisa Stefani, Matteo Gatti, Paolo Fabbrini, Maurizio Rossini, Isotta Galvagni, Davide Gatti, Giovanni Adami, Ombretta Viapiana
Calcified Tissue International.2025;[Epub] CrossRef - The Fungal and Protist Community as Affected by Tillage, Crop Residue Burning and N Fertilizer Application
Luc Dendooven, Valentín Pérez-Hernández, Selene Gómez-Acata, Nele Verhulst, Bram Govaerts, Marco L. Luna-Guido, Yendi E. Navarro-Noya
Current Microbiology.2025;[Epub] CrossRef - Compassion Scale: factor structure and scale validation in Hong Kong adolescents
Steven Sek-yum Ngai, Chau-kiu Cheung, Yuen-hang Ng, Hao-yi Guo, Han-lei Du, Chen Chen, Laing-ming Wong, Qiu-shi Zhou, Wing-tsam Pang
Frontiers in Psychology.2025;[Epub] CrossRef - Translation, cultural adaptation, and validation of the Hebrew version of the Leeds Food Preference Questionnaire
Shiri Sherf-Dagan, Roni Aviram-Friedman, Vital Bahar, Gal Churi, Assaf Buch, Tali Sinai, Vered Kaufman-Shriqui, Ilanit Mahler, Netalie Shloim, Graham Finlayson
Food Quality and Preference.2025; 130: 105520. CrossRef - Examining the effect of an obesity suit role-playing exercise on empathy and weight bias in nutrition students
Inbar Tayar-Wachsberger, Gizel Green, Michael Pinus, Sigal Tepper, Shiri Sherf-Dagan
Nutrition.2025; 138: 112813. CrossRef - Young maize plants impact the bacterial community in Australian cotton‐sown vertisol more than agricultural practices
Luc Dendooven, Daniel Ramírez‐Villanueva, Vanessa Romero‐Yahuitl, Karla E. Zarco‐González, Nilantha Hulugalle, Viliami Heimoana, Nele Verhulst, Bram Govaerts, Yendi E. Navarro‐Noya
Environmental Microbiology Reports.2025;[Epub] CrossRef - Myoelectric Activity of the Peroneal Muscles Following Lateral Ankle Sprain: A Cross-Sectional Analysis
Oriol Casasayas-Cos, Noé Labata-Lezaun, Albert Pérez-Bellmunt, Carlos López-de-Celis, Johke Smit, Xavier Marimon-Serra, Ramón Aiguadé-Aiguadé, Joaquín Sanahuja-Diez-Caballero, Max Canet-Vintró, Luis Llurda-Almuzara
Journal of Functional Morphology and Kinesiology.2025; 10(2): 179. CrossRef - Exploring the Mechanical Properties of Bioprinted Multi-Layered Polyvinyl Alcohol Cryogel for Vascular Applications
Argyro Panieraki, Nasim Mahmoodi, Carl Anthony, Rosemary J. Dyson, Lauren E. J. Thomas-Seale
Journal of Manufacturing and Materials Processing.2025; 9(6): 173. CrossRef -
Soil Characteristics Determine the Effect of Compost or Sterile Compost on Wheat (
Triticum aestivum
L.) Development
Ana Lilia Toriz-Nava, Vanessa Romero-Yahuitl, Karla Estephanía Zarco-González, Mauricio Hernández, Yendi E. Navarro-Noya, Marco Luna Guido, Luc Dendooven
Compost Science & Utilization.2025; 32(3-4): 168. CrossRef - Viral Quasispecies Inference from Single Observations—Mutagens as Accelerators of Quasispecies Evolution
Josep Gregori, Miquel Salicrú, Marta Ibáñez-Lligoña, Sergi Colomer-Castell, Carolina Campos, Alvaro González-Camuesco, Josep Quer
Microorganisms.2025; 13(9): 2029. CrossRef - The eye, a spy hole on human mind: Spontaneous blink rate and amplitude, and their variability, as new psychobiological markers of anxiety
Alon Tomashin, Francesca Fusina, Marco Marino, Alessandro Angrilli, Nick Fogt
PLOS One.2025; 20(12): e0338262. CrossRef - Effect of thyme-ivy syrup on antiviral immune response in patients with mild COVID-19: a prospective, open-label, randomized pilot study
Stephanie Dauth, Stephan M. G. Schäfer, Maximilian Klippstein, Ann C. Foldenauer, Christin Jonetzko, Tanja Roßmanith, Susanne Schiffmann, Maria J. G. T. Vehreschild, Gerd Geisslinger, Frank Behrens, Michaela Koehm
Frontiers in Medicine.2025;[Epub] CrossRef - Sleep health among US Navy afloat versus ashore personnel in the Millennium Cohort Study
Isabel G. Jacobson, Judith Harbertson, Neika Sharifian, Rudolph P. Rull, Christopher T. Steele, Dale W. Russell
Journal of Sleep Research.2024;[Epub] CrossRef - Match running performance preceding scoring and conceding a goal in men’s professional soccer
Marek Konefał, Błażej Szmigiel, Bogdan Bochenek, Ryland Morgans, Piotr Żmijewski
Scientific Reports.2024;[Epub] CrossRef - Which symptom to address in psychological treatment for cancer survivors when fear of cancer recurrence, depressive symptoms, and cancer-related fatigue co-occur? Exploring the level of agreement between three systematic approaches to select the focus of
Susan J. Harnas, Sanne H. Booij, Irene Csorba, Pythia T. Nieuwkerk, Hans Knoop, Annemarie M. J. Braamse
Journal of Cancer Survivorship.2024; 18(6): 1822. CrossRef - The archaeal and bacterial community structure in composted cow manures is defined by the original populations: a shotgun metagenomic approach
Vanessa Romero-Yahuitl, Karla Estephanía Zarco-González, Ana Lilia Toriz-Nava, Mauricio Hernández, Jesús Bernardino Velázquez-Fernández, Yendi E. Navarro-Noya, Marco Luna-Guido, Luc Dendooven
Frontiers in Microbiology.2024;[Epub] CrossRef - The emotion regulation strategies of flourishing adults
Pixie Bella Richard-Sephton, Dimity Ann Crisp, Richard Andrew Burns
Current Psychology.2024; 43(14): 12816. CrossRef - Potential imaging targets in primary head and neck squamous cell carcinoma and lymph node metastases
Jeroen E. van Schaik, Bert van der Vegt, Lorian Slagter-Menkema, Saskia H. Hanemaaijer, Gyorgi B. Halmos, Max J.H. Witjes, Bernard F.A.M. van der Laan, Rudolf S.N. Fehrmann, Sjoukje F. Oosting, Boudewijn E.C. Plaat
American Journal of Otolaryngology.2024; 45(4): 104298. CrossRef - The effectiveness of cognitive-behavioral group therapy on foreign language learning anxiety among university students
Bijon Baroi, Noor Muhammad
Discover Psychology.2024;[Epub] CrossRef - Identification of new head and neck squamous cell carcinoma molecular imaging targets
Jeroen E. van Schaik, Bert van der Vegt, Lorian Slagter-Menkema, Bernard F.A.M. van der Laan, Max J.H. Witjes, Sjoukje F. Oosting, Rudolf S.N. Fehrmann, Boudewijn E.C. Plaat
Oral Oncology.2024; 151: 106736. CrossRef -
Practical application of a minimal important percent difference formulation of Cohen’s
d
JERRY J. Vaske, JAY Beaman, CRAIG A. Miller
Human Dimensions of Wildlife.2024; 29(3): 269. CrossRef - A crossover randomized controlled trial examining the effects of black seed (Nigella sativa) supplementation on IL-1β, IL-6 and leptin, and insulin parameters in overweight and obese women
Elham Razmpoosh, Sara Safi, Mahta Mazaheri, Saman Khalesi, Majid Nazari, Parvin Mirmiran, Azadeh Nadjarzadeh
BMC Complementary Medicine and Therapies.2024;[Epub] CrossRef - Videolaryngoscopy during Urgent Cesarean Delivery: Association with Neonatal Intensive Care Unit Admission
Andrew King, Julie-Ann Thompson, Stewart Hart, Bobby Nossaman
Southern Medical Journal.2024; 117(8): 494. CrossRef - Reduction in Serum Carotenoid Levels Following One Anastomosis Gastric Bypass
Ayelet Harari, Osnat Kaniel, Rom Keshet, Aviv Shaish, Yafit Kessler, Amir Szold, Peter Langer, Asnat Raziel, Nasser Sakran, David Goitein, Jacob Moran-Gilad, Shiri Sherf-Dagan
Nutrients.2024; 16(16): 2596. CrossRef - Population-based GCN method for diagnosis of Alzheimer's disease using brain metabolic or volumetric features
Yanteng Zhang, Linbo Qing, Xiaohai He, Lipei Zhang, Yan Liu, Qizhi Teng
Biomedical Signal Processing and Control.2023; 86: 105162. CrossRef - Effects of Training and Taper on Neuromuscular Fatigue Profile on
100-m Swimming Performance
Felipe Alves Ribeiro, Carlos Dellavechia de Carvalho, Júlia Causin Andreossi, Douglas Rodrigues Messias Miranda, Marcelo Papoti
International Journal of Sports Medicine.2023; 44(05): 329. CrossRef - Nutritional and Lifestyle Behaviors Reported Following One Anastomosis Gastric Bypass Based on a Multicenter Study
Shiri Sherf-Dagan, Reut Biton, Rui Ribeiro, Yafit Kessler, Asnat Raziel, Carina Rossoni, Hasan Kais, Rossela Bragança, Zélia Santos, David Goitein, Octávio Viveiros, Yitka Graham, Kamal Mahawar, Nasser Sakran, Tair Ben-Porat
Nutrients.2023; 15(6): 1515. CrossRef - Functional improvement by behavioural activation for depressed older adults
Noortje P. Janssen, Richard C. Oude Voshaar, Sanne Wassink-Vossen, Gert-Jan Hendriks
European Psychiatry.2023;[Epub] CrossRef - Bacterial Communities in the Rhizosphere of Common Bean Plants (Phaseolus vulgaris L.) Grown in an Arable Soil Amended with TiO2 Nanoparticles
Gabriela Medina-Pérez, Laura Afanador-Barajas, Sergio Pérez-Ríos, Yendi E. Navarro-Noya, Marco Luna-Guido, Fabián Fernández-Luqueño, Luc Dendooven
Agronomy.2023; 14(1): 74. CrossRef - Behavioural Activation versus Treatment as Usual for Depressed Older Adults in Primary Care: A Pragmatic Cluster-Randomised Controlled Trial
Noortje P Janssen, Peter Lucassen, Marcus J H Huibers, David Ekers, Theo Broekman, Judith E Bosmans, Harm Van Marwijk, Jan Spijker, Richard Oude Voshaar, Gert-Jan Hendriks
Psychotherapy and Psychosomatics.2023; 92(4): 255. CrossRef - Silver and Hematite Nanoparticles Had a Limited Effect on the Bacterial Community Structure in Soil Cultivated with Phaseolus vulgaris L.
Karla E. Zarco-González, Jessica D. Valle-García, Yendi E. Navarro-Noya, Fabián Fernández-Luqueño, Luc Dendooven
Agronomy.2023; 13(9): 2341. CrossRef - Effects ofNigella sativasupplementation on blood concentration and mRNA expression of TNF-α, PPAR-γand adiponectin, as major adipogenesis-related markers, in obese and overweight women: a crossover, randomised-controlled trial
Elham Razmpoosh, Sara Safi, Azadeh Nadjarzadeh, Amin Salehi-Abargouei, Mahta Mazaheri, Parvin Mirmiran, David Meyre
British Journal of Nutrition.2023; 129(4): 627. CrossRef - Corticomotor Plasticity Underlying Priming Effects of Motor Imagery on Force Performance
Typhanie Dos Anjos, Aymeric Guillot, Yann Kerautret, Sébastien Daligault, Franck Di Rienzo
Brain Sciences.2022; 12(11): 1537. CrossRef - Recent advances in statistics
Hae-Young Kim
Journal of Periodontal & Implant Science.2022; 52(3): 181. CrossRef - Transcranial Magnetic Stimulation for Long-Term Smoking Cessation: Preliminary Examination of Delay Discounting as a Therapeutic Target and the Effects of Intensity and Duration
Alina Shevorykin, Ellen Carl, Martin C. Mahoney, Colleen A. Hanlon, Amylynn Liskiewicz, Cheryl Rivard, Ronald Alberico, Ahmed Belal, Lindsey Bensch, Darian Vantucci, Hannah Thorner, Matthew Marion, Warren K. Bickel, Christine E. Sheffer
Frontiers in Human Neuroscience.2022;[Epub] CrossRef - Individual cerebrocerebellar functional network analysis decoding symptomatologic dynamics of postoperative cerebellar mutism syndrome
Ko-Ting Chen, Tsung-Ying Ho, Tiing-Yee Siow, Yu-Chiang Yeh, Sheng-Yao Huang
Cerebral Cortex Communications.2022;[Epub] CrossRef - Motivation and Lifestyle-Related Changes among Participants in a Healthy Life Centre: A 12-Month Observational Study
Cille H. Sevild, Christopher P. Niemiec, Sindre M. Dyrstad, Lars Edvin Bru
International Journal of Environmental Research and Public Health.2022; 19(9): 5167. CrossRef - Nitrogen Fertilizer Application Alters the Root Endophyte Bacterial Microbiome in Maize Plants, but Not in the Stem or Rhizosphere Soil
Alejandra Miranda-Carrazco, Yendi E. Navarro-Noya, Bram Govaerts, Nele Verhulst, Luc Dendooven, Junhyun Jeon
Microbiology Spectrum.2022;[Epub] CrossRef - The effect of Nigella sativa on TAC and MDA in obese and overweight women: secondary analysis of a crossover, double blind, randomized clinical trial
Nooshin Abdollahi, Azadeh Nadjarzadeh, Amin Salehi-Abargouei, Hossien Fallahzadeh, Elham Razmpoosh, Elnaz Lorzaedeh, Sara Safi
Journal of Diabetes & Metabolic Disorders.2022; 21(1): 171. CrossRef - Use of the reliable change index to evaluate the effect of a multicomponent exercise program on physical functions
Haruhiko Sato, Masanori Wakida, Ryo Kubota, Takayuki Kuwabara, Kimihiko Mori, Tsuyoshi Asai, Yoshihiro Fukumoto, Jiro Nakano, Kimitaka Hase
Aging Clinical and Experimental Research.2022; 34(12): 3033. CrossRef - Analysis of Airway Management for Cesarean Delivery: Use of Risk and Proportion Differences
Andrew King, Justin Morello, Allison Clark, Adrienne Ray, Colleen Martel, Roneisha McLendon, Anne McConville, Melissa Russo, Liane Germond, Bobby Nossaman
Southern Medical Journal.2022; 115(3): 198. CrossRef - Meta-analytic evidence for a sex-diverging association between alcohol use and body mass index
Eva-Maria Siegmann, Massimiliano Mazza, Christian Weinland, Falk Kiefer, Johannes Kornhuber, Christiane Mühle, Bernd Lenz
Scientific Reports.2022;[Epub] CrossRef - Evaluating the effects of dark chocolate formulated with micro‐encapsulated fermented garlic extract on cardio‐metabolic indices in hypertensive patients: A crossover, triple‐blind placebo‐controlled randomized clinical trial
Salman Mohammadi, Seyed Mohammad Mazloomi, Mehrdad Niakousari, Zohreh Ghaem Far, Amir Azadi, Saeed Yousefinejad, Peyman Jafari, Shiva Faghih
Phytotherapy Research.2022; 36(4): 1785. CrossRef - The association of body mass index with quality of life and working ability: a Finnish population-based study
Aino Vesikansa, Juha Mehtälä, Jari Jokelainen, Katja Mutanen, Annamari Lundqvist, Tiina Laatikainen, Tero Ylisaukko-oja, Tero Saukkonen, Kirsi H. Pietiläinen
Quality of Life Research.2022; 31(2): 413. CrossRef - The effect of synbiotic supplementation on atherogenic indices, hs-CRP, and malondialdehyde, as major CVD-related parameters, in women with gestational diabetes mellitus: a secondary data-analysis of a randomized double-blind, placebo-controlled study
Zohoor Nabhani, Cain C. T. Clark, Nazanin Goudarzi, Alemeh Hariri Far, Elham Razmpoosh
Diabetology & Metabolic Syndrome.2022;[Epub] CrossRef - The effect of Nigella sativa on appetite, anthropometric and body composition indices among overweight and obese women: A crossover, double-blind, placebo-controlled, randomized clinical trial
Sara Safi, Elham Razmpoosh, Hossien Fallahzadeh, Mahta Mazaheri, Nooshin Abdollahi, Majid Nazari, Azadeh Nadjarzadeh, Amin Salehi-Abargouei
Complementary Therapies in Medicine.2021; 57: 102653. CrossRef - Regional differences in the care and outcomes of acute stroke patients in Australia: an observational study using evidence from the Australian Stroke Clinical Registry (AuSCR)
Mitchell Dwyer, Karen Francis, Gregory M Peterson, Karen Ford, Seana Gall, Hoang Phan, Helen Castley, Lillian Wong, Richard White, Fiona Ryan, Lauren Arthurson, Joosup Kim, Dominique A Cadilhac, Natasha A Lannin
BMJ Open.2021; 11(4): e040418. CrossRef - Sitting Posture during Prolonged Computer Typing with and without a Wearable Biofeedback Sensor
Yi-Liang Kuo, Kuo-Yuan Huang, Chieh-Yu Kao, Yi-Ju Tsai
International Journal of Environmental Research and Public Health.2021; 18(10): 5430. CrossRef - LMTK2 as Potential Biomarker for Stratification between Clinically Insignificant and Clinically Significant Prostate Cancer
Alvydas Vezelis, Julija Simiene, Daiva Dabkeviciene, Marius Kincius, Albertas Ulys, Kestutis Suziedelis, Sonata Jarmalaite, Feliksas Jankevicius, Nihal Ahmad
Journal of Oncology.2021; 2021: 1. CrossRef - Experience of Peer Bloggers Using a Social Media Website for Adolescents With Depression or Anxiety: Proof-of-Concept Study
Sana Karim, Kimberly Hsiung, Maria Symonds, Ana Radovic
JMIR Formative Research.2021; 5(7): e26183. CrossRef - Understanding the Impact of Perfluorinated Compounds on Cardiovascular Diseases and Their Risk Factors: A Meta-Analysis Study
Siti Suhana Abdullah Soheimi, Amirah Abdul Rahman, Normala Abd Latip, Effendi Ibrahim, Siti Hamimah Sheikh Abdul Kadir
International Journal of Environmental Research and Public Health.2021; 18(16): 8345. CrossRef - The effect of Nigella sativa supplementation on cardiovascular risk factors in obese and overweight women: a crossover, double-blind, placebo-controlled randomized clinical trial
Elham Razmpoosh, Sara Safi, Azadeh Nadjarzadeh, Hossien Fallahzadeh, Nooshin Abdollahi, Mahta Mazaheri, Majid Nazari, Amin Salehi-Abargouei
European Journal of Nutrition.2021; 60(4): 1863. CrossRef - Overall Survival After Treatment of Localized Prostate Cancer With Proton Beam Therapy, External-Beam Photon Therapy, or Brachytherapy
Yuan Liu, Sagar A. Patel, Ashesh B. Jani, Theresa W. Gillespie, Pretesh R. Patel, Karen D. Godette, Bruce W. Hershatter, Joseph W. Shelton, Mark W. McDonald
Clinical Genitourinary Cancer.2021; 19(3): 255. CrossRef - The Culture of Driving under the Influence of Cannabis and Alcohol in Washington State
Jay Otto, Nicholas Ward, Kari Finley, Shelly Baldwin, Darrin Grondel
Journal of Applied Social Science.2021; 15(1): 29. CrossRef - Role of athletic coach mentors in promoting youth academic success: Evidence from the Add Health national longitudinal study
Kirsten M. Christensen, Elizabeth B. Raposa, Matthew A. Hagler, Lance Erickson, Jean E. Rhodes
Applied Developmental Science.2021; 25(3): 217. CrossRef - Digit ratio (2D:4D) and transgender identity: new original data and a meta-analysis
Eva-Maria Siegmann, Tobias Müller, Isabelle Dziadeck, Christiane Mühle, Bernd Lenz, Johannes Kornhuber
Scientific Reports.2020;[Epub] CrossRef - A Novel Individual Metabolic Brain Network for 18F-FDG PET Imaging
Sheng-Yao Huang, Jung-Lung Hsu, Kun-Ju Lin, Ing-Tsung Hsiao
Frontiers in Neuroscience.2020;[Epub] CrossRef - Evaluation of a Cervical Stabilization Exercise Program for Pain, Disability, and Physical Impairments in University Violinists with Nonspecific Neck Pain
Yi-Liang Kuo, Tsung-Han Lee, Yi-Ju Tsai
International Journal of Environmental Research and Public Health.2020; 17(15): 5430. CrossRef - Large-Scale Screening of 239 Traditional Chinese Medicinal Plant Extracts for Their Antibacterial Activities against Multidrug-Resistant Staphylococcus aureus and Cytotoxic Activities
Gowoon Kim, Ren-You Gan, Dan Zhang, Arakkaveettil Kabeer Farha, Olivier Habimana, Vuyo Mavumengwana, Hua-Bin Li, Xiao-Hong Wang, Harold Corke
Pathogens.2020; 9(3): 185. CrossRef - The relationship between care dependency and pain in nursing home residents
Manuela Hoedl, Silvia Bauer
Archives of Gerontology and Geriatrics.2020; 90: 104166. CrossRef - Minimal effect sizes do not imply minimal effects for differences in long-tailed distributions
Jerry J. Vaske, Jay Beaman, Craig A. Miller
Human Dimensions of Wildlife.2020; 25(3): 281. CrossRef - Interventions promoting active transport to school in children: A systematic review and meta-analysis
Rebecca A. Jones, Nicole E. Blackburn, Catherine Woods, Molly Byrne, Femke van Nassau, Mark A. Tully
Preventive Medicine.2019; 123: 232. CrossRef - Improved parental understanding by an enhanced informed consent form: a randomized controlled study nested in a paediatric drug trial
Nut Koonrungsesomboon, Chanchai Traivaree, Charnunnut Tiyapsane, Juntra Karbwang
BMJ Open.2019; 9(11): e029530. CrossRef - Meta-Analiz: Finans Çalışmaları Üzerine Bir Tartışma
Değer ALPER, Muhammed Fatih AYDEMİR
Muhasebe ve Finansman Dergisi.2019; : 69. CrossRef - Compromised left atrial function and increased size predict raised cavity pressure: a systematic review and meta‐analysis
Ibadete Bytyçi, Gani Bajraktari, Per Lindqvist, Michael Y. Henein
Clinical Physiology and Functional Imaging.2019; 39(5): 297. CrossRef - Community Experience With Acute Respiratory Distress Syndrome in the Prone Position
Fahmida Khan, Christa R. Fistler, Jefferson Mixell, Richard Caplan, Michael T. Vest
Critical Care Explorations.2019; 1(12): e0068. CrossRef - Use of biomarkers in the prediction of culture-proven infection in the surgical intensive care unit
Hussam Ghabra, William White, Michael Townsend, Philip Boysen, Bobby Nossaman
Journal of Critical Care.2019; 49: 149. CrossRef - Medicaid Expansion, HIV Testing, and HIV-Related Risk Behaviors in the United States, 2010–2017
Yunwei Gai, John Marthinsen
American Journal of Public Health.2019; 109(10): 1404. CrossRef - Career orientation and perceived professional competence among clinical research coordinators
Jay W. Rojewski, Ikseon Choi, Janette R. Hill, Yeonjoo Ko, Katherine L. Walters, Sejung Kwon, Linda McCauley
Journal of Clinical and Translational Science.2019; 3(5): 234. CrossRef - Serum 25-hydroxyvitamin D and cardiovascular disease risk factors in women with excessive weight gain during pregnancy and in their offspring at age 5–6 years
Gemma Carreras-Badosa, Cristina Armero-Bujaldón, Laia Solé-Amat, Anna Prats-Puig, Ferran Díaz-Roldán, Pilar Soriano-Rodriguez, Francis de Zegher, Lourdes Ibañez, Judit Bassols, Abel López-Bermejo
International Journal of Obesity.2018; 42(5): 1019. CrossRef - Palaeolithic diet decreases fasting plasma leptin concentrations more than a diabetes diet in patients with type 2 diabetes: a randomised cross-over trial
Maelán Fontes-Villalba, Staffan Lindeberg, Yvonne Granfeldt, Filip K. Knop, Ashfaque A. Memon, Pedro Carrera-Bastos, Óscar Picazo, Madhvi Chanrai, Jan Sunquist, Kristina Sundquist, Tommy Jönsson
Cardiovascular Diabetology.2016;[Epub] CrossRef - Statistical notes for clinical researchers: Sample size calculation 1. comparison of two independent sample means
Hae-Young Kim
Restorative Dentistry & Endodontics.2016; 41(1): 74. CrossRef - Evidence for ACTN3 as a Speed Gene in Isolated Human Muscle Fibers
Siacia Broos, Laurent Malisoux, Daniel Theisen, Ruud van Thienen, Monique Ramaekers, Cécile Jamart, Louise Deldicque, Martine A. Thomis, Marc Francaux, Nir Eynon
PLOS ONE.2016; 11(3): e0150594. CrossRef
 ePub Link
ePub Link Cite
CiteStatistical notes for clinical researchers: effect size
Figure 1 Distribution of control group (solid line) and experimental group (dotted line), and position of Cohen's d = 0.2.1
Figure 1
Statistical notes for clinical researchers: effect size
Examples of results of significant testing using p value and comparative effect size
| Example | Before | After | SD* | Diff. | n | t value | p value | Effect size | Characteristics |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 145 | 142 | 100 | 3 | 100 | 0.382 | Trivial effect & insignificant | ||
| 2 | 145 | 142 | 100 | 3 | 10,000 | 0.001 | Trivial effect & significant | ||
| 3 | 145 | 115 | 100 | 30 | 100 | 0.001 | Substantial effect & significant |
*SD, standard deviation.
Common effect size indices2
| Index | Description | Standard | Comment | |
|---|---|---|---|---|
| Between groups | Cohen's d or Glass's Δ | d or Δ = (Mean1 - Mean2) / SD* d: use pooled SD Δ: use SD of control group | Small 0.2 Medium 0.5 Large 0.8 Very large 1.3 | For continuous outcomes |
| Odds ratio (OR) | OR = odds1 / odds2 | Small 1.5 Medium 2 Large 3 | Degree of association between binary outcomes | |
| Relative risk or risk ratio (RR) | RR = p1 / p2 | Small 2 Medium 3 Large 4 | For binary outcomes, ratio of two proportions | |
| Measures of association | Pearson's r correlation | Range -1 to 1 | Small ± 0.2 Medium ± 0.3 Large ± 0.5 | Measures the degree of linear relationship |
| Pearson r correlation coefficient | Range 0 to 1 | Small 0.04 Medium 0.09 Large 0.25 | Proportion of variance explained | |
*SD, standard deviation.
Interpretation of Cohen's d which represents a standardized difference [(Mean1 - Mean2) / SD*]13
| Relative size | Effect size | % of control group below the mean of experimental group |
|---|---|---|
| 0.0 | 50% | |
| Small | 0.2 | 58% |
| Medium | 0.5 | 69% |
| Large | 0.8 | 79% |
| 1.4 | 92% |
*SD, standard deviation.
Conversion from various statistics to Perason r correlation coefficient association measures3
| Statistic | Conversion formula | Comment |
|---|---|---|
| χ2df = 1 | A single degree of freedom chi-square value divided by the number of cases | |
| t | From t value to r correlation coefficient | |
| F | From F value with single freedom numerator to r | |
| Cohen's d | From Cohen's d to r |
Table 1 Examples of results of significant testing using p value and comparative effect size
*SD, standard deviation.
Table 2 Common effect size indices2
*SD, standard deviation.
Table 3 Interpretation of Cohen's d which represents a standardized difference [(Mean1 - Mean2) / SD*]13
*SD, standard deviation.
Table 4 Conversion from various statistics to Perason r correlation coefficient association measures3