Articles
- Page Path
- HOME > Restor Dent Endod > Volume 38(2); 2013 > Article
- Open Lecture on Statistics Statistical notes for clinical researchers: Evaluation of measurement error 1: using intraclass correlation coefficients
- Hae-Young Kim
-
2013;38(2):-102.
DOI: https://doi.org/10.5395/rde.2013.38.2.98
Published online: May 28, 2013
Department of Dental Laboratory Science & Engineering, Korea University College of Health Science, Seoul, Korea.
- Correspondence to Hae-Young Kim, DDS, PhD. Associate Professor, Department of Dental Laboratory Science & Engineering, Korea University College of Health Science, San 1 Jeongneung 3-dong, Seongbuk-gu, Seoul, Korea 136-703. TEL, +82-2-940-2845; FAX, +82-2-909-3502, kimhaey@korea.ac.kr
©Copyights 2013. The Korean Academy of Conservative Dentistry.
This is an Open Access article distributed under the terms of the Creative Commons Attribution Non-Commercial License (http://creativecommons.org/licenses/by-nc/3.0/) which permits unrestricted non-commercial use, distribution, and reproduction in any medium, provided the original work is properly cited.
- 2,883 Views
- 24 Download
- 61 Crossref
Evaluation of measurement error is a fundamental procedure in clinical studies, field surveys, or experimental researches to confirm the reliability of measurements. If we examine oral health status of a patient, the number of caries teeth or degree of periodontal pocket depth need to be similar when an examiner repeated the measuring procedure (intra-examiner reliability) or when two independent examiners repeated the measuring procedure, to guarantee the reliability of measurement. In experimental researches, confirming small measurement error of measuring machines should be a prerequisite to start the main measuring procedure for the study.
1. Measurement error in our daily lives
We meet many situations which might be subject to measurement error in our daily lives. For example, when we measure body weight using a scale displaying kilograms (kg) to one decimal point, we disregard body weight differences less than 0.1 kg. Similarly, when we check time using a hand-watch with two hands indicating hours and minutes, we implicitly recognize there may be errors ranging up to a few minutes. However, generally we don't worry about these possible errors because we know such a small amount of error comprises a relatively small fraction of the quantity measured. In other words, the measurements may still be reliable even under consideration of the small amount of error. The degree of measurement error could be visualized as a ratio of error variability to total variability. Similarly, degree of reliability could be expressed as a ratio of subject variability to total variability.
2. Reliability: Consistency or absolute agreement?
Reliability is defined as the degree to which a measurement technique can secure consistent results upon repeated measuring on the same objects either by multiple raters or test-retest trials by one observer at different time points. It is necessary to differentiate two different kinds of reliability; consistency or absolute agreement. For example, three raters independently evaluate twenty students' applications for a scholarship on a scale of zero to 100. The first rater is especially harsh and the third one is particularly lenient, but each rater scores consistently. There must be differences among the actual scores which the three raters give. If the purpose is ranking applicants and choosing five students, the difference among raters may not make significantly different results if the 'consistency' was maintained during the entire scoring procedure. However if the purpose is to select students who are rated above or below a preset standard absolute score, the scores from the three raters need to be absolutely similar on a mathematical level. Therefore while we want consistency of the evaluation in the former case, we want to achieve 'absolute agreement' in the later case. Difference of purpose is reflected in the procedure used for reliability calculation.
3. Intraclass correlation coefficient (ICC)
Though there are some important reliability measures, such as Dahlberg's error or Kappa statistics, ICC seems to be the most useful. The ICC is a reliability measure we may use to assess either degree of consistency or absolute agreement. ICC is defined as the ratio of variability between subjects to the total variability including subject variability and error variability.
If we evaluate consistency of an outcome measure which was repeatedly measured, the repetition is regarded as a fixed factor which doesn't involve any errors and the following equation may be applied:
If we evaluate absolute agreement of an outcome measure which was repeatedly measured, the repetition variability needs to be counted because the factor is regarded as a random factor as in the following equation:
Reliability based on absolute agreement is always lower than for consistency because a more stringent criterion is applied.
4. ICC for a single observer and multiple observers
If multiple observers assessed subjects, the average of repetition variability and error variability are applied in calculating ICC. Use of average variability results in higher reliability compared to use of any single rater, because the measurement error is averaged out. When k observers were involved, the ICC equations need to be changed as following:
5. An Example: evaluation of measurement errors
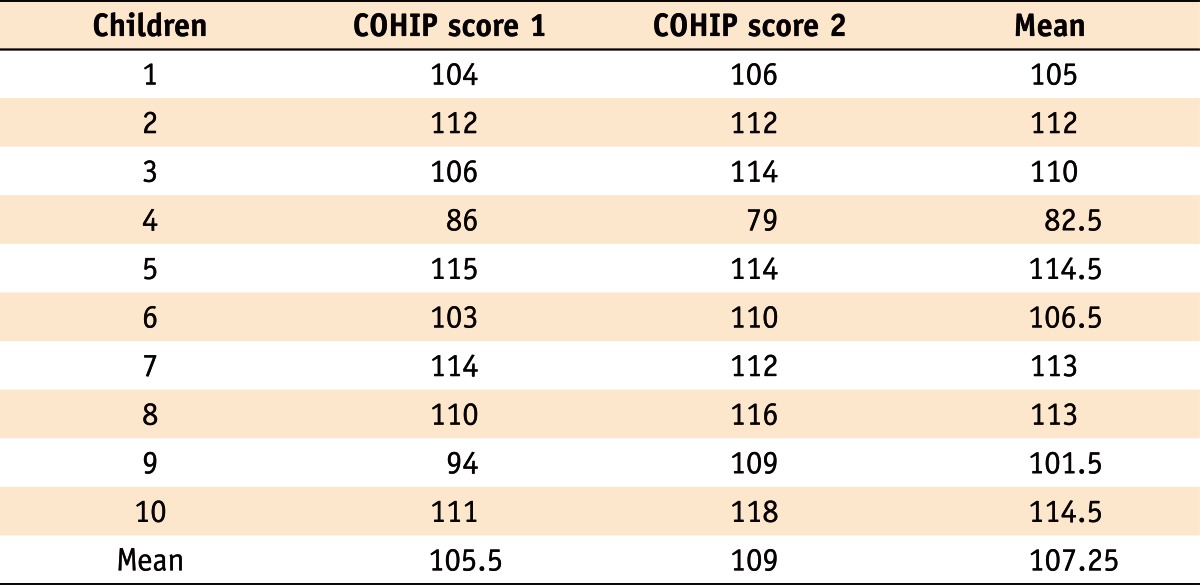
Table 1 displays repeatedly measured scores of the oral health impact profile for children (COHIP), one of the measures for OHRQoL which was obtained among ten 5th-grade school children. The COHIP inventory is a measure ranging from 0 (lowest OHRQoL) to 112 (highest OHRQoL), which assesses level of subjective oral health status by asking questions mainly about oral impacts on daily lives for children. Let's assume that the repeated measurements were obtained by a rater with an appropriate interval to assess test-retest reliability.
To calculate ICC, we need to obtain subject variability and error variability using a statistical package, such as SPSS, as shown in the following procedures.
From the ANOVA table, we use Mean Square (MS) to calculate variances of subject (σ2
child), repetition (σ2
repet), and error (σ2
error) as following:
From the equations above we obtain the variance among children (σ2
child) as 84.78, and variance of repetition (σ2
repet) as 4.13. Then the ICC measuring consistency may be calculated as the proportion of subject (children) variability among total variability excluding variability of repetition which is regarded as a fixed factor.
The same ICC for consistency may be obtained using SPSS, following procedure:
Tables & Figures
REFERENCES
Citations
Citations to this article as recorded by 
- Now you see it, now you don’t: social systematic observation of physical disorder using Google Street View
Lisa M. Pierotte, Lauren Porter, Alaina De Biasi
Journal of Experimental Criminology.2026; 22(2): 329. CrossRef - The Overt Behavior Scale–In Session: A behavioral assessment tool for individuals with acquired brain injury in the inpatient rehabilitation setting
Ileana Herrin, Lindsey Harik, Elizabeth Larkin, Grahame Simpson, Christopher Falco, Chynah Blankenship, Rachelle Wilmore, Nicholas Gut, Glenn Kelly
PM&R.2026; 18(2): 162. CrossRef - Ten Core Concepts for Ensuring Data Equity in Public Health
Yiran Wang, Alicia E. Boyd, Lillian Rountree, Yi Ren, Kate Nyhan, Ruchit Nagar, Jackson Higginbottom, Megan L. Ranney, Harsh Parikh, Bhramar Mukherjee
JAMA Health Forum.2026; 7(1): e256031. CrossRef - Immediate test-retest reliability and agreement of wideband absorbance results in infants
Katrina Moon, Sreedevi Aithal, Venkatesh Aithal, Joseph Kei
International Journal of Audiology.2026; : 1. CrossRef - Analysis of the effectiveness of abdominal contrast-enhanced computed
tomography in evaluating the degree of gastric dilatation
Q. Jing, L. Zhao, R. Yang, N. Hu, D. Wu, Z. Zhang, K. Qiu, X. Zhong
International Journal of Radiation Research.2026; 24(1): 91. CrossRef - Machine Learning-Based Analysis: Retired Customer Attrition and Its Societal Implications
Roza Süleymanoğlu, Hakan Kaya
Ekoist: Journal of Econometrics and Statistics.2026; 0(44): 289. CrossRef - Are Muscle and Fat Loss Predictive of Clinical Events in Pancreatic Cancer? The Importance of Precision Metrics
Mellar P Davis, Nada Bader, James Basting, Erin Vanenkevort, Nicole Koppenhaver, Aalpen Patel, Mudit Gupta, Braxton Lagerman, Mark Wojtowicz
Journal of Pain and Symptom Management.2025; 69(2): 141. CrossRef - Generation of virtual mandibular first molar teeth and accuracy analysis using deep convolutional generative adversarial network
Eun-Jeong Bae, Sun-Young Ihm
Journal of Korean Acedemy of Dental Technology.2024; 46(2): 36. CrossRef - Validity and reliability of Eforto®, a system to (self-)monitor grip strength and muscle fatigability in older persons
Liza De Dobbeleer, Myrthe Manouk Swart, Merle Anne Joëlle Geerds, Remco Johan Baggen, Anne-Jet Sophie Jansen, Rudi Tielemans, Hugo Silva, Siddhartha Lieten, Kurt Barbé, Geeske Peeters, Miriam Marie Rose Vollenbroek-Hutten, René Johannes Franciscus Melis,
Aging Clinical and Experimental Research.2023; 35(4): 835. CrossRef - A three-dimensional method to calculate mechanical advantage in mandibular function
Alejandro Sánchez-Ayala, Alfonso Sánchez-Ayala, Rafaela Cristina Kolodzejezyk, Vanessa Migliorini Urban, Manuel Óscar Lagravère, Nara Hellen Campanha
Journal of Orofacial Orthopedics / Fortschritte der Kieferorthopädie.2023; 84(5): 321. CrossRef - Automated digital enumeration of plasma cells in bone marrow trephine biopsies of multiple myeloma
Jacques A J Malherbe, Kathryn A Fuller, Bob Mirzai, Bradley M Augustson, Wendy N Erber
Journal of Clinical Pathology.2022; 75(1): 50. CrossRef - Nasoalveolar molding and skeletal development in patients with bilateral cleft lip and palate: A retrospective cephalometric study at the completion of growth
M.C. Meazzini, F. Parravicini, N. Cohen, G. Rossetti, L. Autelitano
Journal of Cranio-Maxillofacial Surgery.2022; 50(5): 400. CrossRef - Accuracy and Validity of a Single Inertial Measurement Unit-Based System to Determine Upper Limb Kinematics for Medically Underserved Populations
Charmayne Mary Lee Hughes, Bao Tran, Amir Modan, Xiaorong Zhang
Frontiers in Bioengineering and Biotechnology.2022;[Epub] CrossRef - Skeletal, Dental, and Soft Tissue Changes after Applying Active Skeletonized Sutural Distractor (ASSD) for Class III Malocclusion Patients
Rozita Hassan, Wael Ahmed Bayomy Mohamed, Norma Ab. Rahman, Shaifulizan Ab. Rahman, Norkhafizah Saddki
Applied Sciences.2022; 12(3): 1233. CrossRef - Development and preliminary validation of the Self-Awareness Situation-Based Observation Lists for children with Profound Intellectual and Multiple Disabilities
Juliane Dind, Geneviève Petitpierre
Research in Developmental Disabilities.2022; 121: 104153. CrossRef - Is Maximum Available Hip Extension Range of Motion of the Residual Limb Reached During Passive Prone Lying in the Acute Stage After Dysvascular Transtibial Amputation?
Jason L. Shaw, James M. Hackney, Kristi Shook Vandeloecht, Sean C. Newton, Matthew A. Rainey, Joshua J. Reed, Dani J. Suess, Jennifer N. Tinker
JPO Journal of Prosthetics and Orthotics.2022; 34(3): 165. CrossRef - Long-term biodiversity intervention shapes health-associated commensal microbiota among urban day-care children
Marja I. Roslund, Riikka Puhakka, Noora Nurminen, Sami Oikarinen, Nathan Siter, Mira Grönroos, Ondřej Cinek, Lenka Kramná, Ari Jumpponen, Olli H. Laitinen, Juho Rajaniemi, Heikki Hyöty, Aki Sinkkonen, Damiano Cerrone, Mira Grönroos, Nan Hui, Iida Mäkelä,
Environment International.2021; 157: 106811. CrossRef - Relationship Between Age and Cerebral Hemodynamic Response to Breath Holding: A Functional Near-Infrared Spectroscopy Study
Keerthana Deepti Karunakaran, Katherine Ji, Donna Y. Chen, Nancy D. Chiaravalloti, Haijing Niu, Tara L. Alvarez, Bharat B. Biswal
Brain Topography.2021; 34(2): 154. CrossRef - Validation of the Donkey Pain Scale (DOPS) for Assessing Postoperative Pain in Donkeys
Maria Gláucia Carlos de Oliveira, Valéria Veras de Paula, Andressa Nunes Mouta, Isabelle de Oliveira Lima, Luã Barbalho de Macêdo, Talyta Lins Nunes, Pedro Henrique Esteves Trindade, Stelio Pacca Loureiro Luna
Frontiers in Veterinary Science.2021;[Epub] CrossRef - Three-Dimensional Cephalometric Analysis: The Changes in Condylar Position Pre- and Post-Orthognathic Surgery With Skeletal Class III Malocclusion
Abhinav Shrestha, Shao Hua Song, Han Nyein Aung, Jirayus Sangwatanakul, Nuo Zhou
Journal of Craniofacial Surgery.2021; 32(2): 546. CrossRef - Teachers’ Perceptions of Handwriting Legibility Versus the German Systematic Screening for Motoric-Handwriting Difficulties (SEMS)
Anita M. Franken, Susan R. Harris
OTJR: Occupational Therapy Journal of Research.2021; 41(4): 251. CrossRef - Developing and Psychometric Evaluation of a Reproductive Health Assessment Scale for Married Adolescent Women
Afrouz Mardi, Abbas Ebadi, Zahra Behboodi-Moghadam, Malek Abazari, Nazila Nezhad-Dadgar, Atefeh Shadman
Iranian Journal of Nursing and Midwifery Research.2021; 26(3): 266. CrossRef - Statistical measures of motor, sensory and cognitive performance across repeated robot-based testing
Leif E. R. Simmatis, Spencer Early, Kimberly D. Moore, Simone Appaqaq, Stephen H. Scott
Journal of NeuroEngineering and Rehabilitation.2020;[Epub] CrossRef - Estimation of the postmortem interval based on the human decomposition process
H.T. Gelderman, C.A. Kruiver, R.J. Oostra, M.P. Zeegers, W.L.J.M. Duijst
Journal of Forensic and Legal Medicine.2019; 61: 122. CrossRef - Delineating the number of animal territories using digital mapping and spatial hierarchical clustering in GIS technology
Dorota Kotowska, Piotr Skórka, Kazimierz Walasz
Ecological Indicators.2019; 107: 105670. CrossRef - Age‐related changes in inguinal region anatomy from 0 to 19 years of age
Sean J. Botham, Erin P. Fillmore, Thomas S. Grant, Harvey Davies, Charles Hutchinson, Richard Tunstall
Clinical Anatomy.2019; 32(6): 794. CrossRef - Artificial Neural Networks as a Decision Support Tool in Curriculum Development
Irem Ersöz Kaya
International Journal on Artificial Intelligence Tools.2019; 28(04): 1940004. CrossRef - Reliability and intra-examiner agreement of orthodontic model analysis with a digital caliper on plaster and printed dental models
Vasiliki Koretsi, Constanze Kirschbauer, Peter Proff, Christian Kirschneck
Clinical Oral Investigations.2019; 23(8): 3387. CrossRef - Development of a Post-stroke Upper Limb Rehabilitation Wearable Sensor for Use in Sub-Saharan Africa: A Pilot Validation Study
Charmayne M. L. Hughes, Alexander Louie, Selena Sun, Chloe Gordon-Murer, Gashaw Jember Belay, Moges Baye, Xiaorong Zhang
Frontiers in Bioengineering and Biotechnology.2019;[Epub] CrossRef - A concise shoulder outcome measure: application of computerized adaptive testing to the American Shoulder and Elbow Surgeons Shoulder Assessment
Otho R. Plummer, Joseph A. Abboud, John-Erik Bell, Anand M. Murthi, Anthony A. Romeo, Priyanka Singh, Benjamin M. Zmistowski
Journal of Shoulder and Elbow Surgery.2019; 28(7): 1273. CrossRef - Diaphragmatic Ultrasound Assessment in Subjects With Acute Hypercapnic Respiratory Failure Admitted to the Emergency Department
Gianmaria Cammarota, Ilaria Sguazzotti, Marta Zanoni, Antonio Messina, Davide Colombo, Gian Luca Vignazia, Luigi Vetrugno, Eugenio Garofalo, Andrea Bruni, Paolo Navalesi, Gian Carlo Avanzi, Francesco Della Corte, Giovanni Volpicelli, Rosanna Vaschetto
Respiratory Care.2019; 64(12): 1469. CrossRef - Quality and Correlates of Peer Relationships in Youths with Chronic Pain
Valérie La Buissonnière-Ariza, Dennis Hart, Sophie C. Schneider, Nicole M. McBride, Sandra L. Cepeda, Brandon Haney, Sara Tauriello, Shannon Glenn, Danielle Ung, Peter Huszar, Lisa Tetreault, Erin Petti, S. Parrish Winesett, Eric A. Storch
Child Psychiatry & Human Development.2018; 49(6): 865. CrossRef - Reliability of Oncology Value Framework Outputs: Concordance Between Independent Research Groups
Joseph C Del Paggio, Sierra Cheng, Christopher M Booth, Matthew C Cheung, Kelvin K W Chan
JNCI Cancer Spectrum.2018;[Epub] CrossRef - Assessing the influence of a passive, upper extremity exoskeletal vest for tasks requiring arm elevation: Part II – “Unexpected” effects on shoulder motion, balance, and spine loading
Sunwook Kim, Maury A. Nussbaum, Mohammad Iman Mokhlespour Esfahani, Mohammad Mehdi Alemi, Bochen Jia, Ehsan Rashedi
Applied Ergonomics.2018; 70: 323. CrossRef - A Sensitive Thresholding Method for Confocal Laser Scanning Microscope Image Stacks of Microbial Biofilms
Ting L. Luo, Marisa C. Eisenberg, Michael A. L. Hayashi, Carlos Gonzalez-Cabezas, Betsy Foxman, Carl F. Marrs, Alexander H. Rickard
Scientific Reports.2018;[Epub] CrossRef - Association of Depressive Symptoms with Lapses in Antiretroviral Medication Adherence Among People Living with HIV: A Test of an Indirect Pathway
Jacklyn D. Babowitch, Alan Z. Sheinfil, Sarah E. Woolf-King, Peter A. Vanable, Shannon M. Sweeney
AIDS and Behavior.2018; 22(10): 3166. CrossRef - The short Persian version of motorcycle riding behavior questionnaire and its interchangeability with the full version
Hojjat Hosseinpourfeizi, Homayoun Sadeghi-Bazargani, Kamal Hassanzadeh, Shaker Salarilak, Leili Abedi, Shahryar Behzad Basirat, Hossein Mashhadi Abdolahi, Davoud Khorasani-Zavareh, Amir H. Pakpour
PLOS ONE.2018; 13(8): e0201946. CrossRef - Investigating the Intersession Reliability of Dynamic Brain-State Properties
Derek M. Smith, Yrian Zhao, Shella D. Keilholz, Eric H. Schumacher
Brain Connectivity.2018; 8(5): 255. CrossRef - Supra-threshold auditory brainstem response amplitudes in humans: Test-retest reliability, electrode montage and noise exposure
Garreth Prendergast, Wenhe Tu, Hannah Guest, Rebecca E. Millman, Karolina Kluk, Samuel Couth, Kevin J. Munro, Christopher J. Plack
Hearing Research.2018; 364: 38. CrossRef - Impact of different placement depths on the crestal bone level of immediate versus delayed placed platform-switched implants
Elika Madani, Ralf Smeets, Eric Freiwald, Maryam Setareh Sanj, Ole Jung, Daniel Grubeanu, Henning Hanken, Anders Henningsen
Journal of Cranio-Maxillofacial Surgery.2018; 46(7): 1139. CrossRef - Error measurement in craniometrics: The comparative performance of four popular assessment methods using 2000 simulated cranial length datasets (g-op)
Hayley S.M. Fancourt, Carl N. Stephan
Forensic Science International.2018; 285: 162. CrossRef - Influence of nasoalveolar molding on skeletal development in patients with unilateral cleft lip and palate at 5 years of age
Bengisu Akarsu-Guven, Arda Arisan, Figen Ozgur, Muge Aksu
American Journal of Orthodontics and Dentofacial Orthopedics.2018; 153(4): 489. CrossRef - Assessing the influence of a passive, upper extremity exoskeletal vest for tasks requiring arm elevation: Part I – “Expected” effects on discomfort, shoulder muscle activity, and work task performance
Sunwook Kim, Maury A. Nussbaum, Mohammad Iman Mokhlespour Esfahani, Mohammad Mehdi Alemi, Saad Alabdulkarim, Ehsan Rashedi
Applied Ergonomics.2018; 70: 315. CrossRef - Organizational readiness for implementing change in acute care hospitals: An analysis of a cross‐sectional, multicentre study
Narayan Sharma, Jenny Herrnschmidt, Veerle Claes, Stefanie Bachnick, Sabina De Geest, Michael Simon
Journal of Advanced Nursing.2018; 74(12): 2798. CrossRef - Estimation of myocardial strain from non-rigid registration and highly accelerated cine CMR
Jonathan E. N. Langton, Hoi-Ieng Lam, Brett R. Cowan, Christopher J. Occleshaw, Ruvin Gabriel, Boris Lowe, Suzanne Lydiard, Andreas Greiser, Michaela Schmidt, Alistair A. Young
The International Journal of Cardiovascular Imaging.2017; 33(1): 101. CrossRef - Immediate loading of subcrestally placed dental implants in anterior and premolar sites
Anders Henningsen, Ralf Smeets, Kai Köppen, Susanne Sehner, Frank Kornmann, Alexander Gröbe, Max Heiland, Till Gerlach
Journal of Cranio-Maxillofacial Surgery.2017; 45(11): 1898. CrossRef - Reliability of Pain Measurements Using Computerized Cuff Algometry: A DoloCuff Reliability and Agreement Study
Jack Kvistgaard Olsen, Dilay Kesgin Fener, Eva Elisabet Wæhrens, Anton Wulf Christensen, Anders Jespersen, Bente Danneskiold‐Samsøe, Else Marie Bartels
Pain Practice.2017; 17(6): 708. CrossRef - Validation Study of Maternal Recall on Breastfeeding Duration 6 Years After Childbirth
Emma Ayorkor Amissah, Vijaya Kancherla, Yi-An Ko, Ruowei Li
Journal of Human Lactation.2017; 33(2): 390. CrossRef - Internalized HIV Stigma and Disclosure Concerns: Development and Validation of Two Scales in Spanish-Speaking Populations
Helena Hernansaiz-Garrido, Jesús Alonso-Tapia
AIDS and Behavior.2017; 21(1): 93. CrossRef - Examining Interobserver Reliability of Metric and Morphoscopic Characteristics of the Mandible
Jennifer F. Byrnes, Michael W. Kenyhercz, Gregory E. Berg
Journal of Forensic Sciences.2017; 62(4): 981. CrossRef - The feasibility of immediately loading dental implants in edentulous jaws
Anders Henningsen, Ralf Smeets, Aria Wahidi, Lan Kluwe, Frank Kornmann, Max Heiland, Till Gerlach
Journal of Periodontal & Implant Science.2016; 46(4): 234. CrossRef - Comparison of Test Your Memory and Montreal Cognitive Assessment Measures in Parkinson’s Disease
Emily J. Henderson, Howard Chu, Daisy M. Gaunt, Alan L. Whone, Yoav Ben-Shlomo, Veronica Lyell
Parkinson's Disease.2016; 2016: 1. CrossRef - Caliper Method Versus Digital Photogrammetry for Assessing Arch Height Index in Pregnant Women
Kathryn D. Harrison, Jean L. McCrory
Journal of the American Podiatric Medical Association.2016; 106(6): 406. CrossRef - Accelerometer data requirements for reliable estimation of habitual physical activity and sedentary time of children during the early years - a worked example following a stepped approach
Daniel D. Bingham, Silvia Costa, Stacy A. Clemes, Ash C. Routen, Helen J. Moore, Sally E. Barber
Journal of Sports Sciences.2016; 34(20): 2005. CrossRef - Identifying and Prioritizing Diseases Important for Detection in Adult Hearing Health Care
Samantha J. Kleindienst, Sumitrajit Dhar, Donald W. Nielsen, James W. Griffith, Larry B. Lundy, Colin Driscoll, Brian Neff, Charles Beatty, David Barrs, David A. Zapala
American Journal of Audiology.2016; 25(3): 224. CrossRef - Reproducibility, Reliability, and Validity of Fuchsin‐Based Beads for the Evaluation of Masticatory Performance
Alfonso Sánchez‐Ayala, Arcelino Farias‐Neto, Larissa Soares Reis Vilanova, Marina Abrantes Costa, Ana Clara Soares Paiva, Adriana da Fonte Porto Carreiro, Wilson Mestriner‐Junior
Journal of Prosthodontics.2016; 25(6): 446. CrossRef - Assessment of MMP-1, MMP-8 and TIMP-2 in experimental periodontitis treated with kaempferol
Umut Balli, Burcu Ozkan Cetinkaya, Gonca Cayir Keles, Zeynep Pinar Keles, Sevki Guler, Mehtap Unlu Sogut, Zuleyha Erisgin
Journal of Periodontal & Implant Science.2016; 46(2): 84. CrossRef - Efficacy of sonic-powered toothbrushes for plaque removal in patients with peri-implant mucositis
Jungwon Lee, Jong heun Lim, Jungeun Lee, Sungtae Kim, Ki-Tae Koo, Yang-Jo Seol, Young Ku, Yong-Moo Lee, In-Chul Rhyu
Journal of Periodontal & Implant Science.2015; 45(2): 56. CrossRef - Individual stability of sleep spindle characteristics in healthy young males
T. Eggert, C. Sauter, H. Dorn, A. Peter, M.-L. Hansen, A. Marasanov, H. Danker-Hopfe
Somnologie - Schlafforschung und Schlafmedizin.2015; 19(1): 38. CrossRef - Dental Fear Survey: A Cross-Sectional Study Evaluating the Psychometric Properties of the Brazilian Portuguese Version
Maurício Antônio Oliveira, Miriam Pimenta Vale, Cristiane Baccin Bendo, Saul Martins Paiva, Júnia Maria Serra-Negra
The Scientific World Journal.2014; 2014: 1. CrossRef - Comparison of programs for determining temporal-spatial gait variables from instrumented walkway data: PKmas versus GAITRite
Thorlene Egerton, Pernille Thingstad, Jorunn L Helbostad
BMC Research Notes.2014;[Epub] CrossRef
 ePub Link
ePub Link Cite
CiteStatistical notes for clinical researchers: Evaluation of measurement error 1: using intraclass correlation coefficients
Statistical notes for clinical researchers: Evaluation of measurement error 1: using intraclass correlation coefficients
Repeatedly measured scores of the oral health impact profile for children (COHIP)

Table 1 Repeatedly measured scores of the oral health impact profile for children (COHIP)